关注公众号

关注视频号
入门级AI卡,适配中小推理任务
需要申请更优价格?
联系算力顾问AI推理优化卡,侧重能效与成本平衡
需要申请更优价格?
联系算力顾问国产7nm,AI算力王者
需要申请更优价格?
联系算力顾问48G显存可支持更大模型与批量处理
需要申请更优价格?
联系算力顾问高端加速卡,专为Transformer优
需要申请更优价格?
联系算力顾问面向特定市场的减配版H100
需要申请更优价格?
联系算力顾问面向特定市场的计算卡,满足合规
需要申请更优价格?
联系算力顾问通用计算卡,支持大规模训练与推理
需要申请更优价格?
联系算力顾问极智算提供的主流镜像包括基础镜像、应用镜像、自定义镜像等,模型涵盖大语言模型(如DeepSeek、Qwen、Llama)、视觉模型(如Stable Diffusion)和多模态模型等。
提供多种高性能GPU型号,如NVIDIA A100、H100、H800等,具备强大的计算能力和高显存带宽。支持FP32、TF32等多种混合精度计算,能够满足不同精度需求的计算任务,提升计算效率和资源利用率。同时,优化了对稀疏矩阵运算的支持,减少了AI模型运算中的冗余计算。


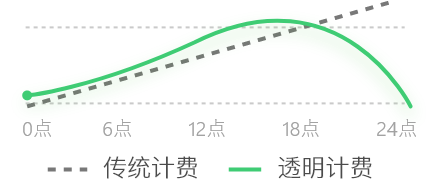
提供按小时、按天、按月按等多种灵活的算力租赁方式,用户可以根据实际需求选择合适的计费模式,避免算力资源浪费,降低使用成本。
支持根据项目需求弹性扩展或收缩算力资源,能够灵活应对不同阶段的算力需求波动,确保资源的高效利用。为用户提供定制化的算力解决方案,满足不同行业和应用场景的特定需求。
基于容器虚拟化技术的轻量级计算资源,通过容器封装实现应用隔离与快速部署,具备弹性伸缩、高资源利用率和跨平台迁移的特性。

弹性扩展与敏捷部署
支持按需动态调整资源分配,适应业务负载变化

微服务架构友好
支持分布式和异构计算,便于独立部署

算力池化优化
将异构算力资源统一管理,实现资源的按需申请与使用

轻量级隔离
通过控制组等技术实现轻量级隔离,减少资源消耗
直接运行在GPU服务器上的算力资源,具备高计算性能、资源独占、高稳定性和强安全性的特点,适合对性能和安全性要求极高的关键业务场景。

高性能算力输出
无虚拟化开销,适合密集型AI任务

高安全性
物理机隔离,适合对安全要求较高的场景

适合高负载应用
对性能要求较高的AI应用,如深度学习等

算力资源独占
避免算力资源争抢,确保AI应用运行的稳定性